
5 Lessons for a Productive AI Engineering Team
How We Ship High-Quality Code at High Speed with Linear and Cursor


At this point, 99% of code in our engineering team is written by AI. The common fear is that this leads to unmaintainable AI slop. Our experience is the exact opposite. AI actually allows us to deliver high-quality code at high speeds. As resource constrained engineers we used to always have to compromise between velocity and quality - now we feel we can have both.
The models have certainly become smarter, but the tooling has also become significantly better. This combination has transformed our entire development workflow. In fact, traditional Agile sprints aren’t a thing for us anymore. We have moved beyond the old rituals into a continuous stream of execution.
Here is what currently works for us, after much experimenting:
1. We prioritize planning with AI
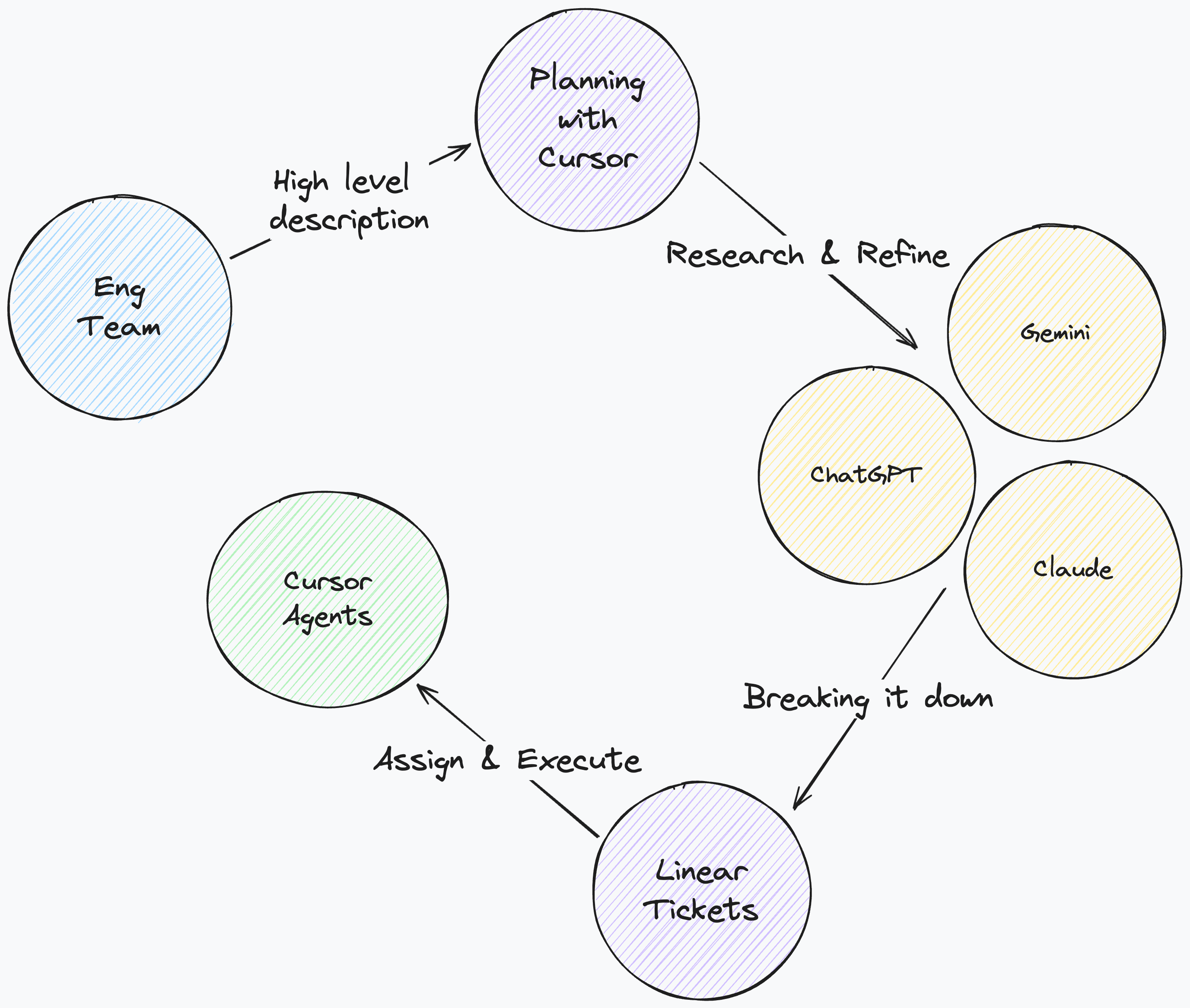
Even though vibe coding with AI felt like we moved fast initially, we quickly realized that relying solely on iterative coding often meant babysitting the agent all day. Instead, we now shift the heavy lifting to the planning phase. Planning now takes precedence over coding.
Sometimes, we spend an entire day just on planning. We iterate the plans with multiple models and AI providers. We refine the architecture until we have the perfect specification. We write multiple detailed tickets with clear, atomic requirements in Linear.
Once the plan is solidified, the building step becomes trivial. We assign Linear tickets in bulk to Cursor agents. We sometimes dispatch tickets to 20 agents at a time to run in parallel. The AI handles the implementation. It writes the boilerplate, connects the APIs, and builds the UI components. This elevates our engineers from “coders” to “system architects” who manage queues and review logic rather than syntax.
2. We let AI find its own work
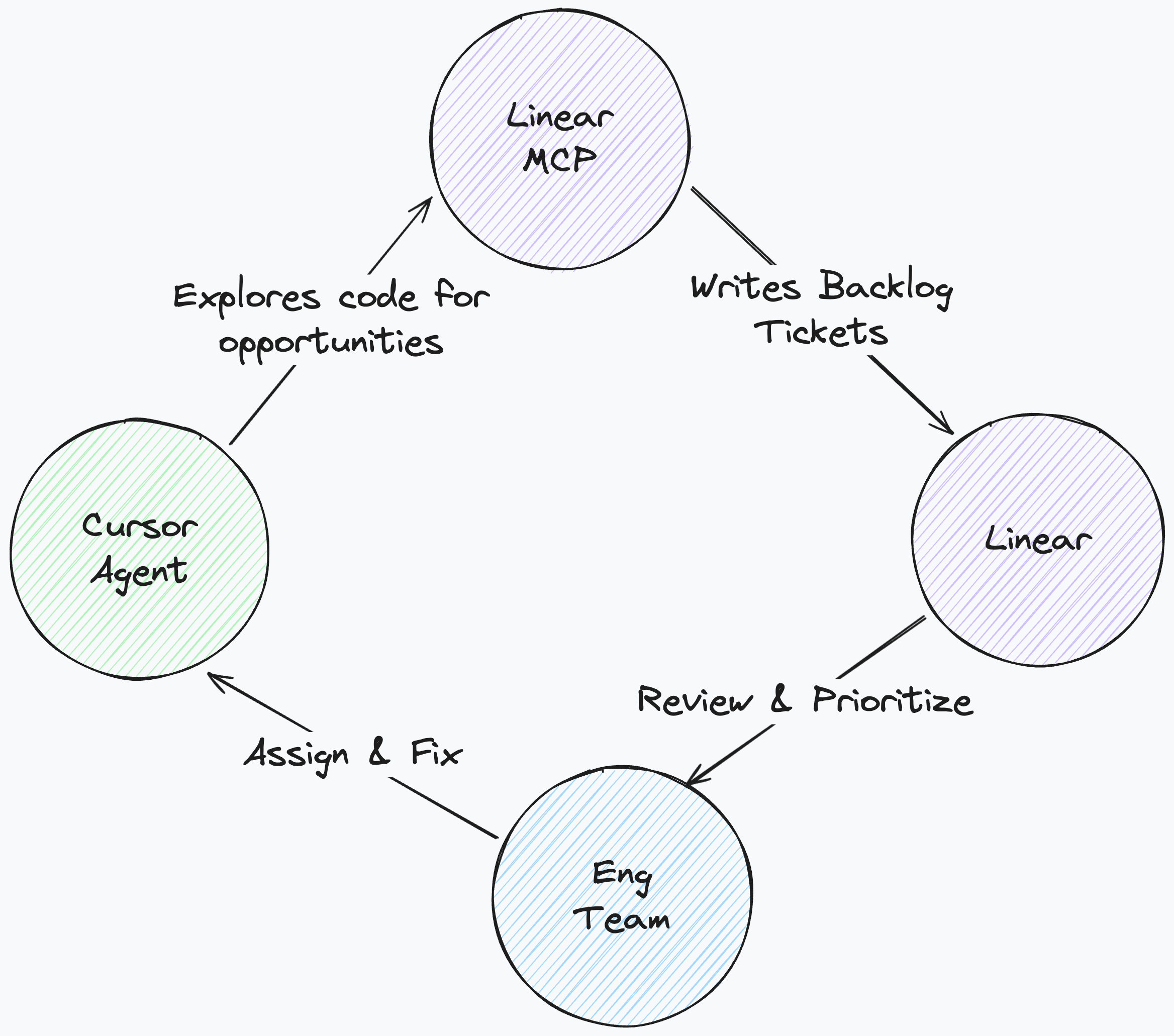
A proactive codebase is better than a reactive one. Waiting for bugs to be reported is inefficient. We let the AI play offense. We often use Cursor (also works with other coding tools such as Claude Code / Codex etc) to proactively scan our codebase for opportunities. It looks for tech debt, refactors, potential performance improvements, and even whole new product features that are implied but missing.
Once identified, we use Linear MCP to automatically generate backlog tickets based on these findings. Our most important task as an engineering team is then to prioritize these tickets to ensure the highest impactful work is done first.
Bonus: We also generate the agent prompt directly in the ticket description. This creates a self-sustaining loop where the ticket is ready to be assigned back to a Cursor agent immediately. This reduces the friction of starting new work to near zero.
3. We trust AI but always verify
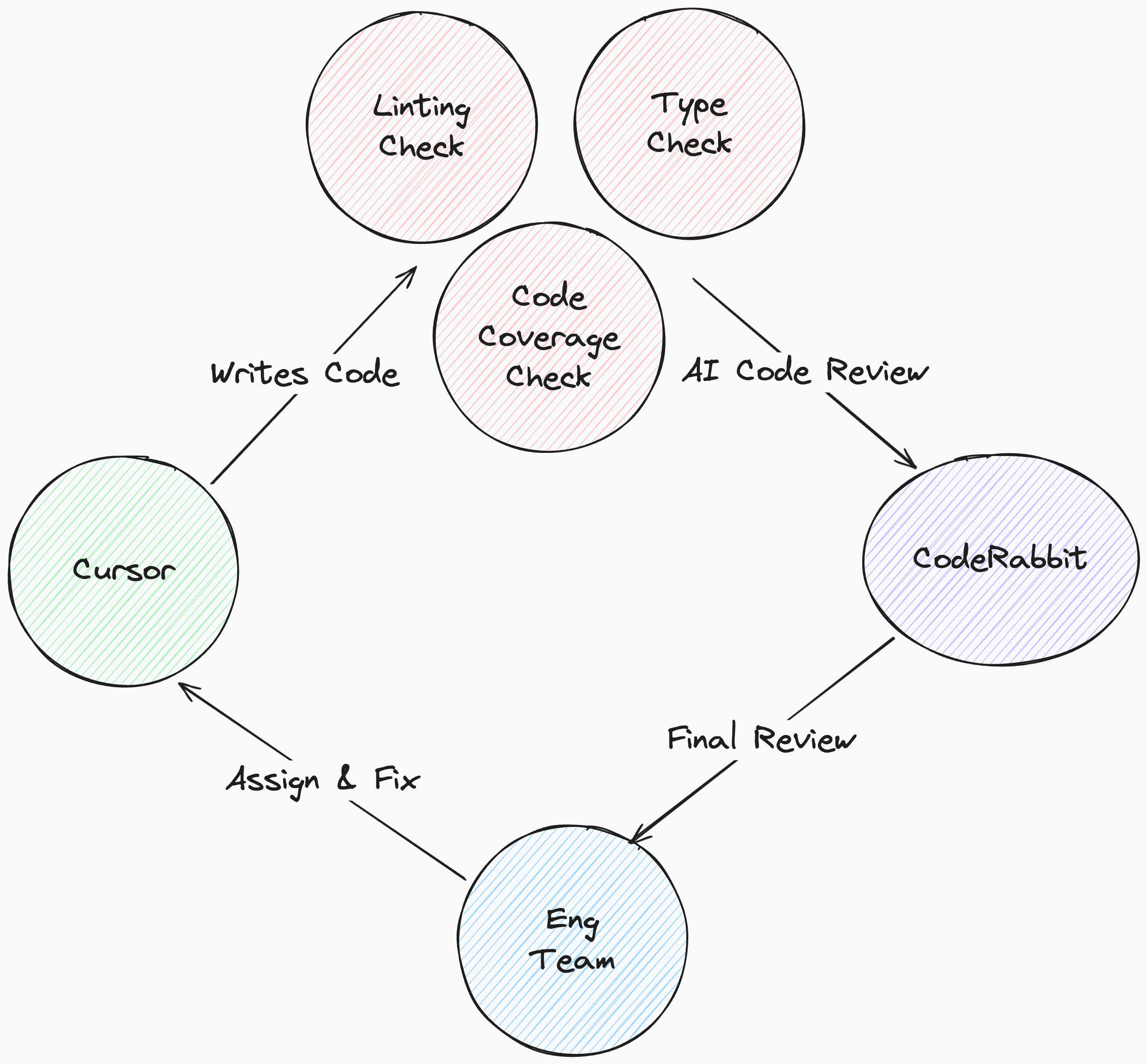
Writing code with AI is incredibly easy and fast but speed without stability is basically racing towards AI slop and technical debt. Agents are trusted, but everything is verified. We use strict linters and rigorous type checking. A strict mandate of 80-100% minimum test coverage has been established as non-negotiable (a standard that has always been hard to prioritize and enforce in traditional engineering teams).
We rely heavily on pre-commit hooks and GitHub Actions. The workflow is binary: the generated code simply does not merge until it passes every single check. There are no exceptions for small fixes. If the coverage drops or the linter complains, the agent must fix it before a human ever reviews it. This preserves our team’s mental energy for high-value problem solving.
Bonus: Reliance solely on human review is risky, as we can suffer from fatigue (especially from the volumes of AI-generated code we need to review). Therefore every PR gets reviewed in depth by an AI code reviewer (we use CodeRabbit but Copilot and Cursor also support this) before a human looks at it. It analyzes the logic, checks for security vulnerabilities, and ensures consistency. We in fact also have a branch rule that all of CodeRabbit’s comments need to be resolved before a PR can get merged.
4. We codify hard earned lessons for AI
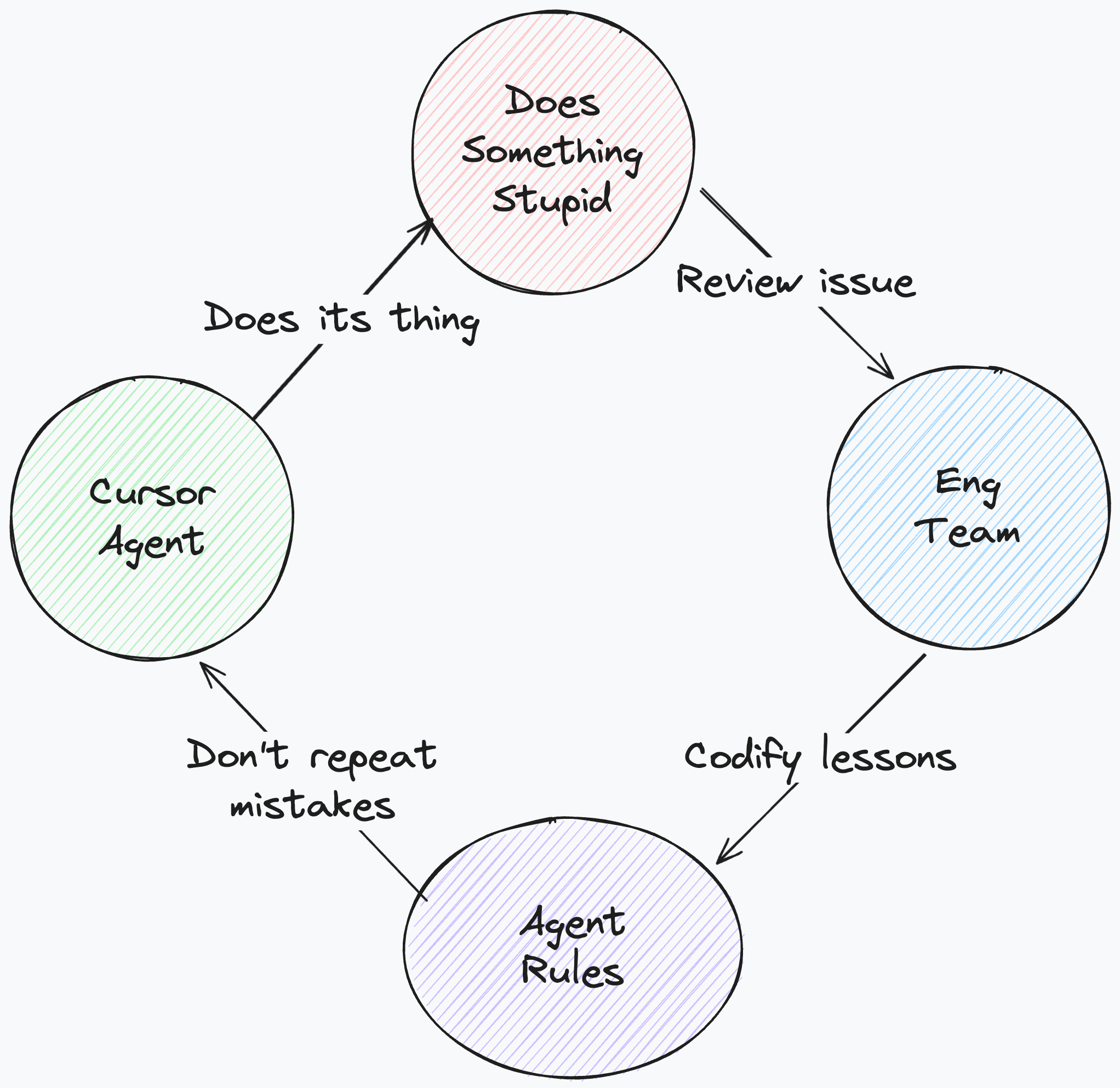
We don’t just hope the AI understands our style; we write it down. We guide the agents with strict, project-specific rules files (we like .cursorrules but there’s also AGENTS.md). For example, one of the key agent rules we have for each project is to commit and push after every meaningful change. This ensures we have a granular history for easy rollbacks when things go wrong (which they often do).
We treat these rules as living documents of our institutional knowledge. Each time we encounter a new issue or a repeating pattern of failure, we add a specific constraint to the rules to prevent it from happening again. Over time this produces a body of work that allows us to move even faster because we’re not bogged down by repeated mistakes of the past.
5. We ensure AI has a great Developer Experience
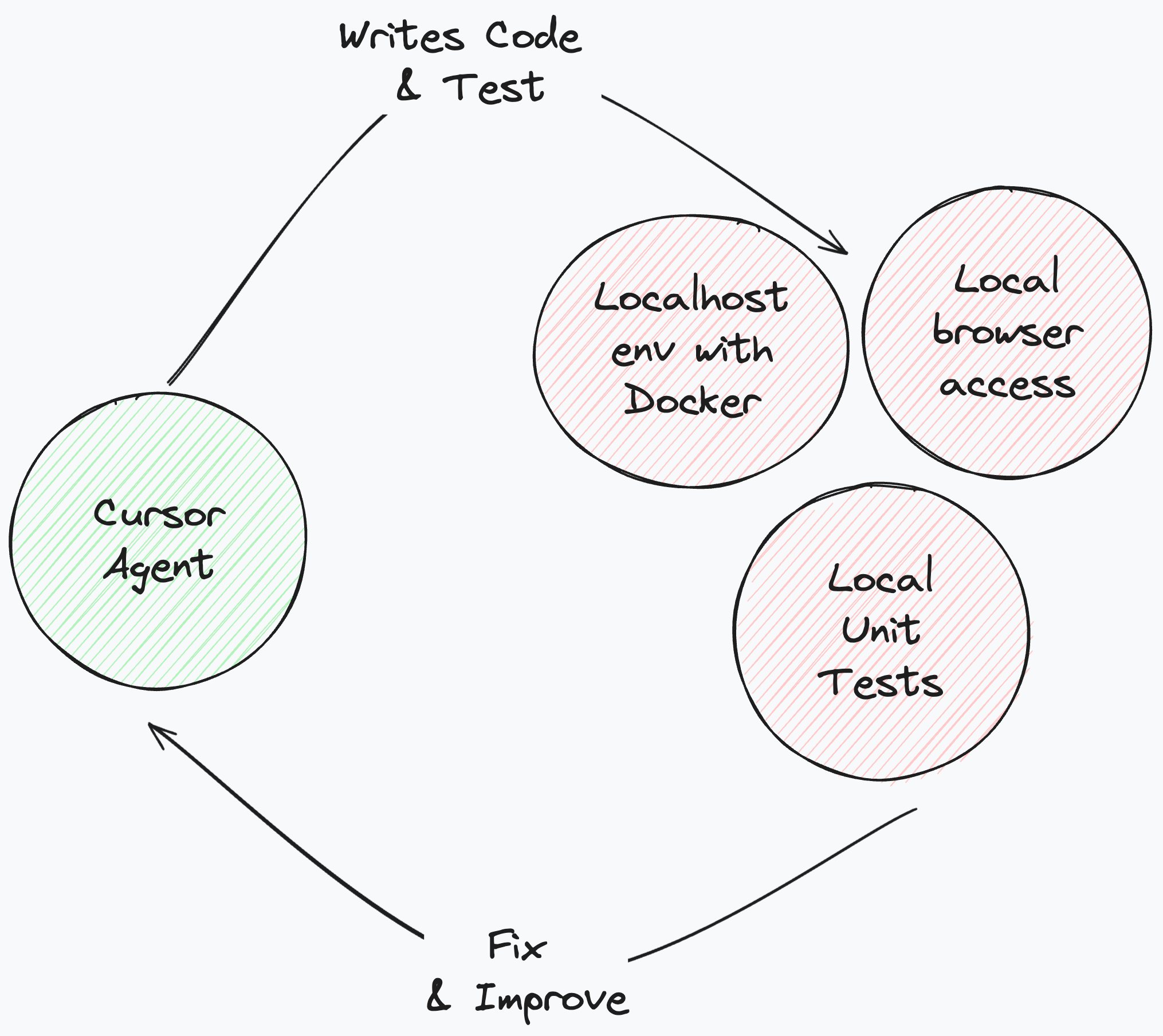
Investing in Developer Experience (DX) has always been key to productivity. With AI, it is the difference between a toy and a tool. A flaky environment confuses a human, but it breaks an agent.
We invest heavily in robust testing harnesses and puppeteering tools that allow the AI for example to control the browser directly or to easily spin up a docker environment. This enables the agent to do more than just write code; it can run the app, click through flows, verify the UI, and iterate until the solution actually works. When the DX is optimized for machines, the AI becomes exponentially more powerful because it can close its own feedback loop.
Of course, we are still learning, breaking things, and rebuilding them better. So while the above might still evolve, it’s just what currently works for us.
I’m curious to know what part of the AI-native transition is clicking for your engineering team, and where you think we might be getting it wrong. Let’s compare notes!