
Anatomy of an Autonomous AI Agent
Exploring the Fundamental Building Blocks That Power Agentic AI Systems

In my previous article, I discussed the rise of agentic AI systems, tools that have the potential to transform business workflows by automating processes from start to finish. These systems aim to replace traditional, static tools with dynamic, adaptive agents capable of tackling complex challenges with unmatched efficiency.
Before we can fully understand how to design and implement entire agentic systems, we need to examine the individual components that make up an autonomous AI agent.
Autonomous agents, like humans, rely on core elements such as identity, memory, planning, and action to function effectively. These components draw inspiration from human behavior, enabling agents to think, learn, and act in ways that feel natural and intuitive. At the same time, AI agents possess unique strengths, such as processing vast amounts of data, optimizing decisions in real time, and scaling operations far beyond human limitations. These insights are grounded in the latest research1 into autonomous agents, providing a clear framework for building systems that are both practical and groundbreaking.
The Four Pillars of Autonomy

At the core of every autonomous AI agent are four critical components: Profile, Memory, Planning, and Action. These systems function as an interconnected system, enabling agents to not only perform tasks but also adapt and improve continuously. Each component addresses a distinct aspect of intelligence, working together to create a cohesive and dynamic entity.
The Profile serves as the agent’s identity and personality, defining its roles, objectives, and the constraints within which it operates. This foundational element shapes how the agent interacts with the world, ensuring that its behavior aligns with its intended purpose and the expectations of users.
The Memory system acts as the agent’s experience bank, storing and retrieving information to inform future actions. By integrating short-term and long-term memory systems, agents can maintain context over ongoing tasks while building a repository of knowledge that enhances their capabilities over time.
The Planning system provides the agent with the ability to strategize and decompose complex objectives into actionable steps. Whether executing static plans or adapting dynamically to real-time feedback, this component ensures that the agent operates methodically and with purpose.
Finally, the Action component translates decisions into tangible outcomes. By leveraging internal reasoning capabilities and external tools, this component enables the agent to execute plans effectively while refining its approach based on feedback.
Together, these four pillars form the foundation of modern autonomous AI agents, empowering them to function as adaptive, intelligent entities in complex environments.
Profile: Defining the Agent’s Identity

The profile component establishes the foundation for an agent’s behavior and decision-making, defining its purpose, personality, and role. By tailoring these attributes, the profile ensures agents interact effectively with their environment and align with user expectations, making them more relatable, functional, and human-like.
Without a clear profile, an agent is just a tool - not an expert.
Basic Attributes
Basic attributes outline the core characteristics of an agent, such as its expertise, role, or professional domain. For instance, a financial advisor agent may be assigned attributes emphasizing analytical rigor and familiarity with economic trends. These attributes act as the agent’s “resume,” ensuring its actions are informed by relevant context and knowledge.
Psychological Traits
Psychological traits shape how agents behave, mimicking personalities like empathetic, assertive, or collaborative. For example, a customer service agent designed to handle sensitive issues might prioritize empathy and patience, creating a supportive and positive user experience. These traits allow agents to engage users in a manner that feels intuitive and human-centered.
Social Context
Social context defines the agent’s relationships and collaborative dynamics. This can include specifying its role within a team or its interaction model with other agents and humans. For instance, in a collaborative software project, one agent might function as a “project manager,” delegating tasks to others, while another acts as a “developer,” implementing the assigned components.
Creating Profiles
Manually Defined Profiles: Manually specifying profiles involves explicitly writing descriptions and constraints for the agent. For instance, “You are an analytical product manager focused on delivering data-driven insights to drive innovation.” While this approach ensures precision, it can be labor-intensive, particularly for large-scale implementations.
Automated Profile Generation: Automated systems can generate diverse profiles by leveraging AI models. For example, by seeding profiles with a few initial traits, such as age or industry, the model can produce variations suited for different applications, saving time while ensuring scalability.
Dataset-Informed Profiles: Real-world data can enhance profiles, making agents more relevant to specific scenarios. For instance, a sales agent’s profile could be informed by regional customer preferences, enabling it to tailor interactions effectively.
The profile component acts as the backbone of an agent’s identity, shaping its interactions and decision-making processes. By carefully defining attributes, psychological traits, and social roles, profiles ensure agents align with their intended purpose and resonate with user expectations. Whether crafted manually, generated through AI, or informed by real-world data, robust profiles empower agents to perform seamlessly and adapt dynamically across various applications. This foundational layer ensures that every interaction, memory, and action reflects the agent’s unique purpose and value.
Memory: The Agent’s Experience Bank

The memory component empowers agents to accumulate, recall, and reflect upon experiences, creating a feedback loop that enhances learning and adaptability. Inspired by human cognitive processes, the memory system integrates short-term and long-term components to navigate dynamic environments effectively.
An agent’s memory isn’t just storage; it’s the lens through which it learns and improves.
Memory Structures
Much like human memory, an agent's memory is divided into short-term and long-term systems. Short-term memory acts as a transient workspace for managing immediate context. This is akin to remembering what someone said just moments ago during a conversation - it helps maintain coherence and enables meaningful responses. For example, an AI assistant might use short-term memory to hold recent customer queries, ensuring its answers remain relevant and conversational.
Long-term memory provides a more durable repository, consolidating key insights over time. Similar to how people remember important milestones or professional lessons learned, agents use long-term memory to store and retrieve knowledge that informs future decisions. A sales forecasting agent, for instance, could analyze years of sales data stored in long-term memory to detect seasonal trends and recommend optimal inventory levels.
Memory Formats
The way memories are stored also plays a vital role in agent performance.
Natural Language Memory: Memories can be recorded as plain text, capturing the nuances of user interactions or observations. This format is highly interpretable and enables rich, context-aware decision-making. An agent managing customer support might store previous interactions as natural language logs, allowing it to ensure continuity in follow-ups.
Embedding-Based Memory: By encoding memories as vector embeddings, agents can retrieve relevant information efficiently based on similarity searches. To illustrate, when recommending a product, an agent could match current user preferences with past customer behavior stored in embeddings.
Structured Data: Agents can store information in structured formats like databases or hierarchical lists. This allows for systematic organization and precise querying, such as retrieving specific financial records during audits or customer details for targeted marketing.
Memory Operations
Memory operations govern how agents interact with stored information.
Writing Memory: Storing new information is akin to taking detailed meeting notes. An agent must decide which details to preserve - filtering for relevance and avoiding duplication. For instance, an agent tracking project updates might consolidate repetitive task notes into a concise summary.
Reading Memory: Retrieving stored knowledge requires prioritization based on relevance, recency, and importance. An agent planning a delivery route could pull recent traffic data (recency), prioritize major road closures (relevance), and consider weather conditions (importance) to optimize decision-making.
Reflection: Reflection allows agents to summarize past experiences and derive insights. Similar to how a team evaluates project outcomes to refine future strategies, an agent could analyze failed and successful customer service interactions to improve its performance.
Hybrid Memory Systems
By integrating short-term and long-term memory, agents gain the ability to reason effectively in both immediate and strategic contexts. Imagine an inventory management agent that tracks real-time stock levels (short-term) while leveraging historical sales trends (long-term) to anticipate seasonal demand spikes. This dynamic capability enhances both day-to-day operations and long-term planning.
The memory component is like a knowledge management system in a business; short-term memory resembles an active project board for immediate tasks, while long-term memory acts as an archive of insights and strategies.
When designed effectively, it ensures continuity, allowing agents to draw from past experiences to inform present decisions. By integrating and balancing both short-term and long-term memory, agents can adapt to immediate demands while leveraging historical knowledge to make strategic, consistent, and impactful choices across dynamic and complex scenarios.
Planning: Charting the Path Forward
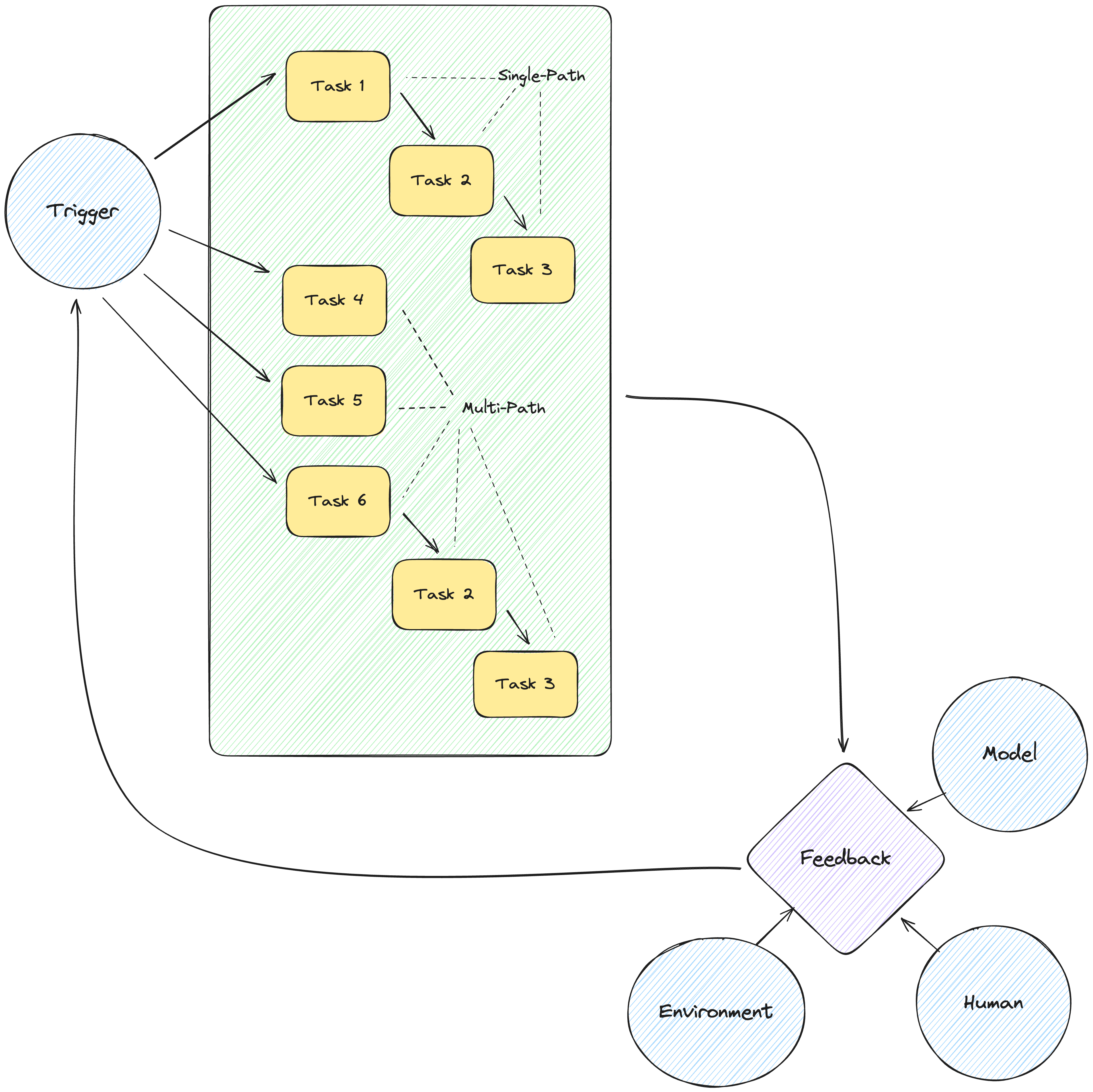
The planning component provides agents with the ability to deconstruct complex goals into actionable steps, enabling coherent and methodical execution. Much like humans, agents rely on structured planning to approach challenges in a manageable way.
Good planning isn’t about predicting the future - it’s about adapting to it.
Planning Without Feedback
In some scenarios, agents generate and execute plans without receiving intermediate feedback to adjust their strategies. These plans are created using predefined frameworks or processes, suitable for straightforward tasks.
Single-Path Reasoning: This involves breaking down a task into sequential steps, with each step leading directly to the next. It mirrors a to-do list approach, where completing one step logically progresses to the next. For instance, an agent organizing an event might follow steps such as booking a venue, arranging catering, and finalizing invitations in a fixed sequence. While effective for predictable scenarios, this approach lacks adaptability when conditions change.
Multi-Path Reasoning: This strategy involves exploring multiple possible solutions concurrently, akin to brainstorming different routes to solve a problem. By evaluating various pathways, the agent can select the most promising one. For example, a product design agent might explore different prototypes simultaneously and refine the most viable option based on user testing results.
External Planning Tools: In complex or domain-specific scenarios, agents can integrate external tools to enhance planning. A healthcare scheduling agent could use specialized software to optimize appointments based on patient preferences, doctor availability, and equipment constraints. By leveraging such tools, agents can generate precise and efficient plans.
Planning without feedback is like a project manager creating a detailed plan for a product launch and sticking to it rigidly, regardless of market changes or team setbacks. While this approach ensures speed and consistency for predictable tasks, it falls short in dynamic scenarios where flexibility is crucial.
Planning With Feedback
For dynamic and unpredictable environments, agents employ iterative planning processes that incorporate feedback to refine their strategies.
Environmental Feedback: This involves adjusting plans based on changes in the environment or observed outcomes. A logistics agent may revise a delivery route in real time to account for traffic congestion, ensuring timely deliveries despite evolving road conditions.
Human Feedback: By soliciting guidance from users, agents can align their strategies with human preferences and expectations. A design assistant might request feedback on a prototype before finalizing its design, allowing iterative refinements based on client input.
Model Feedback: Agents can self-assess their reasoning and actions using internal evaluative models. A financial analysis agent might critique its investment recommendations against historical data patterns, iterating on its conclusions to enhance accuracy.
Planning with feedback, on the other hand, is akin to a sales team adjusting its pitch in real time based on customer reactions during a meeting. While more resource-intensive and complex, it enables agents to respond effectively to unforeseen challenges, making it indispensable for tasks involving long-term reasoning or high variability.
Each method has its place: the former is ideal for stable, routine operations, while the latter is better suited to complex, evolving environments where adaptability is key.
Action: From Decision to Execution

The action component serves as the bridge between planning and real-world impact, transforming decisions into tangible outcomes. It is the final, yet pivotal, step where all preceding components converge to interact with the environment effectively.
The ultimate measure of intelligence is action.
Action Goals
Actions taken by an agent are goal-oriented and shaped by the overarching objectives of its tasks. These goals often fall into three primary categories:
Task Completion: In many scenarios, the agent’s purpose is to complete specific, well-defined tasks. For example, an AI agent in e-commerce may automate order processing and inventory updates, ensuring operational efficiency. Similarly, in the context of software development, agents may execute unit tests or compile code based on predefined requirements.
Communication: Effective communication is a crucial action goal, especially for agents working in collaborative or customer-facing roles. For instance, a customer support agent may communicate empathetically with users to resolve issues, while collaborative agents within a development team exchange structured information to coordinate efforts.
Environment Exploration: Certain agents are designed to explore unfamiliar territories or environments to gather data or expand their capabilities. For example, a supply chain agent might analyze market trends by scanning competitor websites and extracting useful insights, refining its decision-making process iteratively.
Action Production
Translating decisions into executable actions can occur through various strategies:
Memory-Based Actions: Actions often leverage stored knowledge. For instance, an agent retrieving prior successful strategies for handling specific customer complaints can adaptively address recurring issues. Memory-driven actions ensure continuity and relevance in execution.
Plan-Based Actions: Some actions strictly adhere to pre-generated plans. A marketing automation agent, for example, may execute a pre-approved campaign schedule, systematically deploying ads, and analyzing engagement metrics without deviation unless prompted by dynamic inputs.
Action Space
The breadth of possible actions an agent can perform is dictated by its capabilities and integration with external tools:
External Tools: Agents often utilize APIs, databases, or specialized models to extend their action space. For instance, a financial agent might access external economic data APIs to inform portfolio adjustments.
Internal Knowledge: LLMs' inherent reasoning, conversational, and common-sense capabilities enable agents to make informed decisions. For example, an AI consultant might provide nuanced business recommendations purely based on its internal reasoning processes.
Action Impact
Actions inevitably have consequences that ripple across various dimensions:
Environmental Changes: Agents can alter their surroundings, such as updating inventory levels in a warehouse management system or generating new content for social media campaigns.
Internal Adaptations: Actions often result in updated internal states. An agent completing a sub-task may refine its long-term memory with insights, improving its future performance.
Triggered Follow-Up Actions: In complex workflows, one action may cascade into others. For instance, sending an invoice could trigger payment tracking and follow-up reminders if deadlines aren’t met.
The action component is akin to a customer service representative implementing solutions. Without a robust system, actions might be reactive or misaligned with company goals. With an optimized action system, like an agent using CRM data, every interaction aligns with customer needs and business objectives, whether solving a support ticket, upselling a product, or adjusting based on feedback.
By effectively leveraging internal knowledge, external tools, and real-time inputs, the action component ensures agents not only execute tasks efficiently but continuously improve their performance, driving meaningful business outcomes.
Capability Acquisition: Building Agent Skills
While the architecture of an agent serves as its “hardware,” the true effectiveness of an autonomous AI agent lies in its ability to acquire the “software” it needs: task-specific skills, knowledge, and experiences. Capability acquisition is a critical process that enables agents to grow and adapt, transforming them from general-purpose tools into highly specialized entities capable of handling complex and diverse tasks.
Capability acquisition is the key to transforming autonomous agents from static tools into adaptive, versatile systems that thrive in complex and dynamic environments.
Acquiring Capabilities Through Fine-Tuning
One of the most effective ways to enhance agent performance is by fine-tuning large language models (LLMs) using task-specific datasets. These datasets can be created through several methods, including human annotation, LLM-generated content, or real-world data collection. For example, fine-tuning with datasets such as those collected from e-commerce platforms or web interactions, provide valuable context to optimize agents for domain-specific challenges.
Fine-tuning allows agents to integrate substantial task-specific knowledge into their model parameters, making them highly effective at addressing particular use cases. However, this method is most suitable for open-source LLMs, as it requires direct access to the model’s architecture.
Enhancing Capabilities Without Fine-Tuning
When fine-tuning is not feasible, agents can acquire new capabilities through techniques such as prompt engineering and mechanism engineering.
Prompt engineering leverages the natural language understanding of LLMs to describe desired behaviors or provide few-shot examples. For instance, including intermediate reasoning steps in a prompt can significantly improve an agent’s problem-solving capabilities. Similarly, prompts that incorporate social or reflective contexts can enhance conversational adaptability and self-awareness.
Mechanism engineering, on the other hand, involves creating new operational strategies for agents. This can include iterative trial-and-error processes, where agents learn from feedback to refine their actions, or the development of self-driven evolution systems, where agents set goals and explore environments autonomously. These strategies enable agents to continuously improve their performance without altering their underlying model parameters.
Building a Learning Framework
Agents can also acquire new capabilities through frameworks that emphasize experience accumulation and collaborative problem-solving. By storing and refining successful actions in a memory system or a skill library, agents can draw on past experiences to solve similar tasks more efficiently in the future. Collaborative approaches, where agents exchange knowledge and adjust their roles dynamically, further enhance their ability to tackle complex problems that require collective intelligence.
Evaluation: Measuring Agent Performance
Evaluating the performance and effectiveness of LLM-based autonomous agents is a challenging yet crucial task. While these agents hold the potential to revolutionize workflows across industries, assessing their capabilities requires a nuanced approach that balances qualitative insights with quantitative rigor.
Evaluation is not just about measuring performance - it’s about understanding how well agents align with human needs and expectations while excelling in task execution.
Subjective Evaluation
Subjective evaluation focuses on human judgment to assess the agent’s capabilities in tasks where no standardized datasets or metrics exist. This approach is particularly useful for evaluating aspects such as user-friendliness, creativity, or the agent’s ability to mimic human-like behavior.
Human Annotation: In this method, human evaluators score or rank the agent’s outputs. For instance, annotators might rate agents on qualities like engagement, helpfulness, and honesty, as seen in studies where agents’ outputs are compared against human benchmarks. This approach captures nuanced feedback that reflects the real-world impact of an agent’s behavior.
Turing Test: The Turing Test involves asking human evaluators to differentiate between outputs produced by agents and those created by humans. If the evaluators are unable to distinguish between the two, the agent demonstrates human-like performance. This strategy has been widely used to assess agents’ ability to generate human-like responses, emotional intelligence, and decision-making skills.
Objective Evaluation
Objective evaluation employs quantifiable metrics to measure agent performance, offering a more systematic and scalable approach. This method focuses on three key aspects: metrics, protocols, and benchmarks.
Metrics
Evaluation metrics are designed to capture specific dimensions of agent performance.
Task Success: Metrics such as success rate, accuracy, and goal completion are used to assess how effectively the agent achieves its objectives.
Human Similarity: Metrics like dialogue similarity, trajectory accuracy, and mimicry of human responses gauge how closely the agent’s behavior aligns with human norms.
Efficiency: This includes measures like planning speed, cost of execution, and inference time, which evaluate the agent’s operational efficiency.
Protocols
Protocols define how metrics are applied in different contexts:
Real-World Simulation: Agents are tested in immersive environments such as games or simulators, where task success and human similarity metrics can be observed in action.
Social Evaluation: Agents are assessed based on their interactions in collaborative or competitive settings, analyzing qualities like teamwork, empathy, and communication.
Multi-Task Evaluation: A diverse set of tasks from different domains is used to measure the agent’s generalization capability.
Software Testing: Metrics like bug detection rate and test coverage are used to evaluate agents in coding and debugging scenarios.
Benchmarks
Benchmarks provide standardized environments and datasets for consistent evaluation. Examples include AgentBench2 for general-purpose assessments, WebShop3 for e-commerce capabilities, and EmotionBench4 for evaluating emotional intelligence. These benchmarks ensure that agents are tested against a wide range of real-world challenges, providing valuable insights into their adaptability and robustness.
Challenges: Key Barriers Ahead
While LLM-based autonomous agents have achieved significant milestones, the field is still in its early stages. There are numerous challenges that researchers and developers must overcome to unlock the full potential of these systems. Below, we outline some of the most critical challenges shaping the trajectory of development in this domain.
Role-Playing Capability
Autonomous agents are often required to assume specific roles, such as a researcher, programmer, or teacher, to complete tasks effectively. While LLMs can simulate some roles convincingly, they struggle with less common or emerging roles, as well as aspects of human cognition like self-awareness in conversations. This limitation stems from the datasets on which these models are trained, which may lack diverse role-specific data. Fine-tuning with curated datasets or designing optimized prompts and architectures may improve role-playing, but balancing these enhancements with general-purpose performance remains a significant challenge.
Generalized Human Alignment
For agents to serve humans effectively, they must align with human values. However, in applications like real-world simulations, agents may need to replicate both positive and negative human behaviors to provide accurate models of societal dynamics. This dual alignment is particularly challenging as most LLMs are optimized for positive, unified human values. The development of prompting strategies or controlled re-alignment techniques is needed to tailor agents to diverse scenarios without compromising ethical standards.
Prompt Robustness
The integration of complex modules like memory and planning requires structured, reliable prompts to ensure consistent agent behavior. However, even slight modifications to prompts can cause significant deviations in agent outputs. This challenge is exacerbated by the interconnected nature of agent modules, where changes in one prompt may affect others. Developing unified and resilient prompt frameworks that are robust across diverse tasks and LLMs remains an open problem.
Hallucination
Hallucination, where agents confidently produce incorrect information, poses a major challenge in high-stakes applications. For example, in coding tasks, hallucinations can generate erroneous outputs with potentially severe consequences. Addressing hallucinations requires iterative feedback mechanisms, improved training datasets, and fail-safe systems to validate outputs before execution.
Knowledge Boundary
LLMs possess extensive knowledge from training on vast datasets, which can sometimes hinder their ability to simulate realistic human behaviors. For instance, when tasked with replicating user behaviors with limited prior knowledge, agents may leverage their extensive training corpus inappropriately. Constraining agents to appropriate knowledge levels requires innovative methods for controlling context and access to information.
Efficiency
Agents often need to query LLMs multiple times for tasks such as memory retrieval, planning, and decision-making. The inherent slowness of LLMs due to their autoregressive architecture creates significant efficiency bottlenecks. Addressing this requires optimizing agent workflows, leveraging caching or batching strategies, and developing faster inference techniques.
In upcoming issues, we’ll dive even deeper into how to design autonomous agents. Subscribe to stay ahead of the curve and learn how to shape the future of work.
Wang, L., Ma, C., Feng, X. et al. A survey on large language model based autonomous agents. Front. Comput. Sci. 18, 186345 (2024).
Liu X, Yu H, Zhang H, Xu Y, Lei X, Lai H, Gu Y, Ding H, Men K, Yang K, Zhang S, Deng X, Zeng A, Du Z, Zhang C, Shen S, Zhang T, Su Y, Sun H, Huang M, Dong Y, Tang J. AgentBench: evaluating LLMs as agents. 2023, arXiv preprint arXiv: 2308.03688
Yao S, Chen H, Yang J, Narasimhan K. WebShop: towards scalable real-world Web interaction with grounded language agents. In: Proceedings of the 36th Conference on Neural Information Processing Systems. 2022, 20744−20757
Huang J T, Lam M H, Li E J, Ren S, Wang W, Jiao W, Tu Z, Lyu M R. Emotionally numb or empathetic? Evaluating how LLMs feel using emotionbench. 2024, arXiv preprint arXiv: 2308.03656